
- Linux Device Driver Tutorial – Part 1 | Introduction
- Linux Device Driver Tutorial – Introduction
- Linux – Introduction
- Linux Architecture
- Kernel Space
- User Space
- Linux Kernel Modules
- Linux Device drivers
- Filesystem drivers
- System calls
- Advantages of LKM
- Differences Between Kernel Modules and User Programs
- Difference Between Kernel Drivers and Kernel Modules
- Device Driver
- Types
- Character Device
- Block Device
- Network Device
- Video Explanation
- Как написать свой первый Linux device driver
- Подготовительные работы
- Инициализация
- Удаление
- Linux Device Drivers: Tutorial for Linux Driver Development
- Getting started with the Linux kernel module
- Creating a kernel module
- Registering a character device
- The file_operations structure
- The printk function
- Using memory allocated in user mode
- Building the kernel module
- Loading and using the module
- Conclusion
Linux Device Driver Tutorial – Part 1 | Introduction
Last Updated on: July 22nd, 2022
This article is the Series on Linux Device Drivers and carries the discussion on character drivers and their implementation. The aim of this series is to provide easy and practical examples that anyone can understand. This is the Linux Device Driver Tutorial Part 1 – Introduction.
Before we start with programming, it’s always better to know some basic things about Linux and its drivers. We will focus on the basics in this tutorial.
You can find a video explanation of this tutorial here. You can also find all the Linux device driver’s video playlists here.
Linux Device Driver Tutorial – Introduction
Linux – Introduction
Linux is a free open-source operating system (OS) based on UNIX that was created in 1991 by Linus Torvalds. Users can modify and create variations of the source code, known as distributions, for computers and other devices.
Linux Architecture
Linux is primarily divided into User Space & Kernel Space. These two components interact through a System Call Interface – which is a predefined and matured interface to Linux Kernel for Userspace applications. The below image will give you a basic understanding.
 Kernel Space
Kernel Space
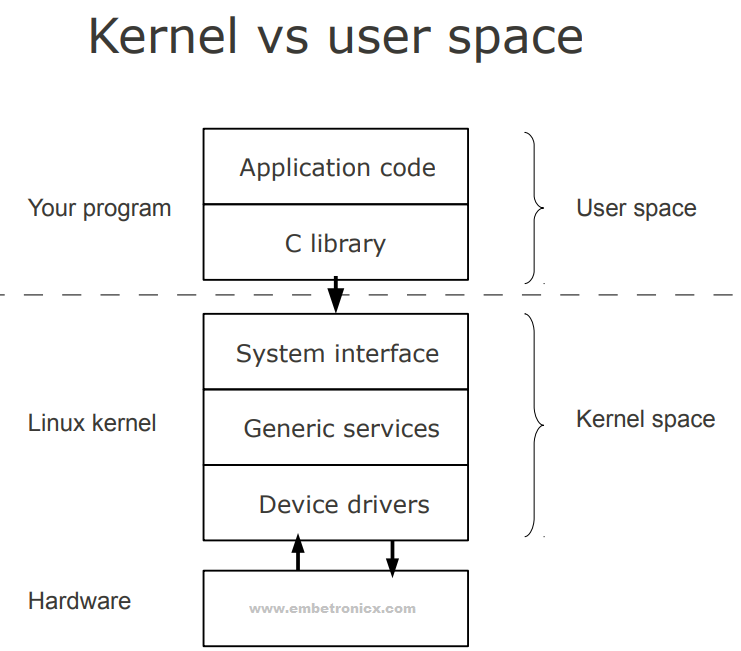 Kernel Space
Kernel SpaceKernel space is where the kernel (i.e., the core of the operating system) executes (i.e., runs) and provides its services.
User Space
User Space is where the user applications are executed.
Linux Kernel Modules
Kernel modules are pieces of code that can be loaded and unloaded into the kernel upon demand. They extend the functionality of the kernel without the need to reboot the system.
Custom codes can be added to Linux kernels via two methods.
The basic way is to add the code to the kernel source tree and recompile the kernel.
A more efficient way is to do this is by adding code to the kernel while it is running. This process is called loading the module, where the module refers to the code that we want to add to the kernel.
Since we are loading these codes at runtime and they are not part of the official Linux kernel, these are called loadable kernel modules (LKM), which is different from the “base kernel”. The base kernel is located in /boot directory and is always loaded when we boot our machine whereas LKMs are loaded after the base kernel is already loaded. Nonetheless, this LKM is very much part of our kernel and they communicate with the base kernel to complete their functions.
LKMs can perform a variety of task, but basically, they come under three main categories,
Linux Device drivers
A device driver is designed for a specific piece of hardware. The kernel uses it to communicate with that piece of hardware without having to know any details of how the hardware works.
Filesystem drivers
A filesystem driver interprets the contents of a filesystem (which is typically the contents of a disk drive) as files and directories and such. There are lots of different ways of storing files and directories and such on disk drives, on network servers, and in other ways. For each way, you need a filesystem driver. For example, there’s a filesystem driver for the ext2 filesystem type used almost universally on Linux disk drives. There is one for the MS-DOS filesystem too, and one for NFS.
System calls
Userspace programs use system calls to get services from the kernel. For example, there are system calls to read a file, to create a new process, and to shut down the system. Most system calls are integral to the system and very standard, so are always built into the base kernel (no LKM option).
But you can invent a system call of your own and install it as an LKM. Or you can decide you don’t like the way Linux does something and override an existing system call with an LKM of your own.
Advantages of LKM
One major advantage they have is that we don’t need to keep rebuilding the kernel every time we add a new device or if we upgrade an old device. This saves time and also helps in keeping our base kernel error-free.
LKMs are very flexible, in the sense that they can be loaded and unloaded with a single line of command. This helps in saving memory as we load the LKM only when we need them.
Differences Between Kernel Modules and User Programs
Kernel modules have separate address spaces. A module runs in kernel space. An application runs in userspace. The system software is protected from user programs. Kernel space and user space have their own memory address spaces.
Kernel modules have higher execution privileges. Code that runs in kernel space has greater privilege than code that runs in userspace.
Kernel modules do not execute sequentially. A user program typically executes sequentially and performs a single task from beginning to end. A kernel module does not execute sequentially. A kernel module registers itself in order to serve future requests.
Kernel modules use different header files. Kernel modules require a different set of header files than user programs require.
Difference Between Kernel Drivers and Kernel Modules
- A kernel module is a bit of compiled code that can be inserted into the kernel at run-time, such as with insmod or modprobe .
- A driver is a bit of code that runs in the kernel to talk to some hardware device. It “drives” the hardware. Almost every bit of hardware in your computer has an associated driver.
Device Driver
A device driver is a particular form of software application that is designed to enable interaction with hardware devices. Without the required device driver, the corresponding hardware device fails to work.
A device driver usually communicates with the hardware by means of the communications subsystem or computer bus to which the hardware is connected. Device drivers are operating system-specific and hardware-dependent. A device driver acts as a translator between the hardware device and the programs or operating systems that use it.
Types
In the traditional classification, there are three kinds of the device:
- Character device
- Block device
- Network device
In Linux, everything is a file. I mean Linux treats everything as a File even hardware.
Character Device
A char file is a hardware file that reads/writes data in character by character fashion. Some classic examples are keyboard, mouse, serial printer. If a user uses a char file for writing data no other user can use the same char file to write data that blocks access to another user. Character files use synchronize Technic to write data. Of you observe char files are used for communication purposes and they can not be mounted.
Block Device
A block file is a hardware file that reads/writes data in blocks instead of character by character. This type of file is very much useful when we want to write/read data in a bulk fashion. All our disks such are HDD, USB, and CDROMs are block devices. This is the reason when we are formatting we consider block size. The writing of data is done in an asynchronous fashion and it is CPU-intensive activity. These device files are used to store data on real hardware and can be mounted so that we can access the data we have written.
Network Device
A network device is, so far as Linux’s network subsystem is concerned, an entity that sends and receives packets of data. This is normally a physical device such as an ethernet card. Some network devices though are software only such as the loopback device which is used for sending data to yourself.
This is all about the basics of Linux and Linux device drivers. We setup the ubuntu and Raspberry Pi for the Linux device driver development in our next tutorial.
Video Explanation
Как написать свой первый Linux device driver
Здравствуйте, дорогие хабрачитатели.
Цель данной статьи — показать принцип реализации драйверов устройств в системе Linux, на примере простого символьного драйвера.
Для меня же, главной целью является подвести итог и сформировать базовые знания для написания будущих модулей ядра, а также получить опыт изложения технической литературы для публики, т.к. через полгода я буду выступать со своим дипломным проектом (да я студент).
Это моя первая статья, пожалуйста не судите строго!
Получилось слишком много букв, поэтому я принял решение разделить статью на три части:
Часть 1 — Введение, инициализация и очистка модуля ядра.
Часть 2 — Функции open, read, write и trim.
Часть 3 — Пишем Makefile и тестируем устройство.
Перед вступлением, хочу сказать, что здесь будут изложены базовые вещи, более подробная информация будет изложена во второй и последней части данной статьи.
Подготовительные работы
Спасибо Kolyuchkin за уточнения.
Символьный драйвер (Char driver) — это, драйвер, который работает с символьными устройствами.
Символьные устройства — это устройства, к которым можно обращаться как к потоку байтов.
Пример символьного устройства — /dev/ttyS0, /dev/tty1.
К вопросу про проверсию ядра:
Драйвер представляет каждое символьное устройство структурой scull_dev, а также предостовляет интерфейс cdev к ядру.
Устройство будет представлять связный список указателей, каждый из которых указывает на структуру scull_qset.
Для наглядности посмотрите на картинку.
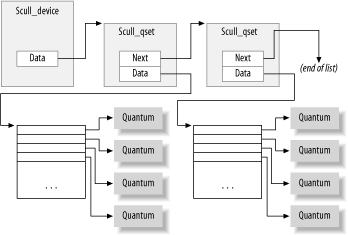
Для регистрации устройства, нужно задать специальные номера, а именно:
MAJOR — старший номер (является уникальным в системе).
MINOR — младший номер (не является уникальным в системе).
В ядре есть механизм, который позволяет регистрировать специализированные номера вручную, но такой подход нежелателен и лучше вежливо попросить ядро динамически выделить их для нас. Пример кода будет ниже.
После того как мы определили номера для нашего устройства, мы должны установить связь между этими номерами и операциями драйвера. Это можно сделать используя структуру file_operations.
В ядре есть специальные макросы module_init/module_exit, которые указывают путь к функциям инициализации/удаления модуля. Без этих определений функции инициализации/удаления никогда не будут вызваны.
Здесь будем хранить базовую информацию об устройстве.
Последним этапом подготовительной работы будет подключение заголовочных файлов.
Краткое описание приведено ниже, но если вы хотите копнуть поглубже, то добро пожаловать на прекрасный сайт: lxr
Инициализация
Теперь давайте посмотрим на функцию инициализации устройства.
Первым делом, вызывая alloc_chrdev_region мы регистрируем диапазон символьных номеров устройств и указываем имя устройства. После вызовом MAJOR(dev) мы получаем старший номер.
Далее проверяется вернувшееся значение, если оно является кодом ошибки, то выходим из функции. Стоит отметить, что при разработке реального драйвера устройства следует всегда проверять возвращаемые значения, а также указатели на любые элементы (NULL?).
Если вернувшееся значение не является кодом ошибки, продолжаем выполнять инициализацию.
Выделяем память, делая вызов функции kmalloc и обязательно проверяем указатель на NULL.
Стоит упомянуть, что вместо вызова двух функций kmalloc и memset, можно использовать один вызов kzalloc, который выделят область памяти и инициализирует ее нулями.
Продолжаем инициализацию. Главная здесь функция — это scull_setup_cdev, о ней мы поговорим чуть ниже. MKDEV служит для хранения старший и младших номеров устройств.
Возвращаем значение или обрабатываем ошибку и удаляем устройство.
Выше были представлены структуры scull_dev и cdev, которые реализуют интерфейс между нашим устройством и ядром. Функция scull_setup_cdev выполняет инициализацию и добавление структуры в систему.
Удаление
Функция scull_cleanup_module вызывается при удалении модуля устройства из ядра.
Обратный процесс инициализации, удаляем структуры устройств, освобождаем память и удаляем выделенные ядром младшие и старшие номера.
С удовольствием выслушаю конструктивную критику и буду ждать feedback’a.
Если вы нашли ошибки или я не правильно изложил материал, пожалуйста, укажите мне на это.
Для более быстрой реакции пишите в ЛС.
Linux Device Drivers: Tutorial for Linux Driver Development
Programming a device driver for Linux requires a deep understanding of the operating system and strong development skills. To help you master this complex domain, Apriorit driver development experts created this tutorial.
We’ll show you how to write a device driver for Linux (5.3.0 version of the kernel). In doing so, we’ll discuss the kernel logging system, principles of working with kernel modules, character devices, the file_operations structure, and accessing user-level memory from the kernel. You’ll also get code for a simple Linux driver that you can augment with any functionality you need.
This article will be useful for developers studying Linux driver development.

Driver Development Team
Contents:
Getting started with the Linux kernel module
The Linux kernel is written in the C and Assembler programming languages. C implements the main part of the kernel, while Assembler implements architecture-dependent parts. That’s why we can use only these two languages for Linux device driver development. We cannot use C++, which is used for the Microsoft Windows kernel, because some parts of the Linux kernel source code (e.g. header files) may include keywords from C++ (for example, delete or new ), while in Assembler we may encounter lexemes such as ‘ : : ’ .
There are two ways of programming a Linux device driver:
- Compile the driver along with the kernel, which is monolithic in Linux.
- Implement the driver as a kernel module, in which case you won’t need to recompile the kernel.
In this tutorial, we’ll develop a driver in the form of a kernel module. A module is a specifically designed object file. When working with modules, Linux links them to the kernel by loading them to the kernel address space.
Module code has to operate in the kernel context. This requires a developer to be very attentive. If a developer makes a mistake when implementing a user-level application, it will not cause problems outside the user application in most cases. But mistakes in the implementation of a kernel module will lead to system-level issues.
Luckily for us, the Linux kernel is resistant to non-critical errors in module code. When the kernel encounters such errors (for example, null pointer dereferencing), it displays the oops message — an indicator of insignificant malfunctions during Linux operation. After that, the malfunctioning module is unloaded, allowing the kernel and other modules to work as usual. In addition, you can analyze logs that precisely describe non-critical errors. Keep in mind that continuing driver execution after an oops message may lead to instability and kernel panic.

The kernel and its modules represent a single program module and use a single global namespace. In order to minimize the namespace, you must control what’s exported by the module. Exported global characters must have unique names and be cut to the bare minimum. A commonly used workaround is to simply use the name of the module that’s exporting the characters as the prefix for a global character name.
With this basic information in mind, let’s start writing our driver for Linux.
Creating a kernel module
We’ll start by creating a simple prototype of a kernel module that can be loaded and unloaded. We can do that with the following code:
The my_init function is the driver initialization entry point and is called during system startup (if the driver is statically compiled into the kernel) or when the module is inserted into the kernel. The my_exit function is the driver exit point. It’s called when unloading a module from the Linux kernel. This function has no effect if the driver is statically compiled into the kernel.
These functions are declared in the linux/module.h header file. The my_init and my_exit functions must have identical signatures such as these:
Now our simple module is complete. Let’s teach it to log in to the kernel and interact with device files. These operations will be useful for Linux kernel driver development.
Registering a character device
Device files are usually stored in the /dev folder. They facilitate interactions between the user space and the kernel code. To make the kernel receive anything, you can just write it to a device file to pass it to the module serving this file. Anything that’s read from a device file originates from the module serving it.
There are two groups of device files:
- Character files — Non-buffered files that allow you to read and write data character by character. We’ll focus on this type of file in this tutorial.
- Block files — Buffered files that allow you to read and write only whole blocks of data.
Linux systems have two ways of identifying device files:
- Major device numbers identify modules serving device files or groups of devices.
- Minor device numbers identify specific devices among a group of devices specified by a major device number.
We can define these numbers in the driver code, or they can be allocated dynamically. In case a number defined as a constant has already been used, the system will return an error. When a number is allocated dynamically, the function reserves that number to prevent other device files from using the same number.
To register a character device, we need to use the register_chrdev function:
Here, we specify the name and the major number of a device to register it. After that, the device and the file_operations structure will be linked. If we assign 0 to the major parameter, the function will allocate a major device number on its own. If the value returned is 0, this indicates success, while a negative number indicates an error. Both device numbers are specified in the 0–255 range.

The device name is a string value of the name parameter. This string can pass the name of a module if it registers a single device. We use this string to identify a device in the /sys/devices file. Device file operations such as read, write, and save are processed by the function pointers stored within the file_operations structure. These functions are implemented by the module, and the pointer to the module structure identifying this module is also stored within the file_operations structure (more about this structure in the next section).
The file_operations structure
In the Linux 5.3.0 kernel, the file_operations structure looks like this:
If this structure contains functions that aren’t required for your driver, you can still use the device file without implementing them. A pointer to an unimplemented function can simply be set to 0. After that, the system will take care of implementing the function and make it behave normally. In our case, we’ll just implement the read function.
As we’re going to ensure the operation of only a single type of device with our Linux driver, our file_operations structure will be global and static. After it’s created, we’ll need to fill it statically like this:
The declaration of the THIS_MODULE macro is contained in the linux/export.h header file. We’ll transform the macro into a pointer to the module structure of the required module. Later, we’ll write the body of the function with a prototype, but for now we have only the device_file_read pointer to it:
The file_operations structure allows us to develop several functions that will register and revoke the registration of the device file. To register a device file, we use the following code:
device_file_major_number is a global variable that contains the major device number. When the lifetime of the driver expires, this global variable will be used to revoke the registration of the device file.
In the code above, we’ve added the printk function that logs kernel messages. Pay attention to the KERN_NOTICE and KERN_WARNING prefixes in all listed printk format strings. NOTICE and WARNING indicate the priority level of a message. Levels range from insignificant ( KERN_DEBUG ) to critical ( KERN_EMERG ), alerting about kernel instability. This is the only difference between the printk function and the printf library function.
The printk function
The printk function forms a string, which we add to the circular buffer. From there the klog daemon reads it and sends it to the system log. Implementing the printk allows us to call this function from any point in the kernel. Use this function carefully, as it may cause overflow of the circular buffer, meaning the oldest message will not be logged.
Our next step is writing a function for unregistering the device file. If a device file is successfully registered, the value of the device_file_major_number will not be 0. This value allows us to revoke the registration of a file using the unregister_chrdev function, which we declare in the linux/fs.h file. The major device number is the first parameter of this function, followed by a string containing the device name. The register_chrdev and the unresister_chrdev functions have similar contents.
To unregister a device, we use the following code:
The next step in implementing functions for our module is allocating and using memory in user mode. Let’s see how it’s done.
Using memory allocated in user mode
The read function we’re going to write will read characters from a device. The signature of this function must be appropriate for the function from the file_operations structure:
Let’s look at the filep parameter — the pointer to the file structure. This file structure allows us to get necessary information about the file we’re working with, data related to this file, and more. The data we’ve read is allocated in the user space at the address specified by the second parameter — buffer. The number of bytes to be read is defined in the len parameter, and we start reading bytes from a certain offset defined in the offset parameter. After executing the function, the number of bytes that have been successfully read must be returned. Then we must refresh the offset.
To work with information from the device file, the user allocates a special buffer in the user-mode address space. Then, the read function copies the information to this buffer. The address to which a pointer from the user space points and the address in the kernel address space may have different values. That’s why we cannot simply dereference the pointer.
When working with these pointers, we have a set of specific macros and functions we declare in the linux/uaccess.h file. The most suitable function in our case is copy_to_user. Its name speaks for itself: it copies specific data from the kernel buffer to the buffer allocated in the user space. It also verifies if a pointer is valid and if the buffer size is large enough. Here’s the code for the copy_to_user prototype:
First of all, this function must receive three parameters:
- A pointer to the buffer
- A pointer to the data source
- The number of bytes to be copied
If there are any errors in execution, the function will return a value other than 0. In case of successful execution, the value will be 0. The copy_to_user function contains the _user macro that documents the process. Also, this function allows us to find out if the code uses pointers from the address space correctly. This is done using Sparse, an analyzer for static code. To be sure that it works correctly, always mark the user address space pointers as _user.
Here’s the code for implementing the read function:
With this function, the code for our driver is ready. Now it’s time to build the kernel module and see if it works as expected.
Building the kernel module
In modern kernel versions, the makefile does most of the building for a developer. It starts the kernel build system and provides the kernel with information about the components required to build the module.
A module built from a single source file requires a single string in the makefile . After creating this file, you only need to initiate the kernel build system with the obj-m := source_file_name.o command. As you can see, here we’ve assigned the source file name to the module — the *.ko file.
If there are several source files, only two strings are required for the kernel build:
To initialize the kernel build system and build the module, we need to use the make –C KERNEL_MODULE_BUILD_SYSTEM_FOLDER M=`pwd` modules command. To clean up the build folder, we use the make –C KERNEL_MODULES_BUILD_SYSTEM_FOLDER M=`pwd` clean command.
The module build system is commonly located in /lib/modules/`uname -r`/build. Now it’s time to prepare the module build system. To build our first module, execute the make modules_prepare command from the folder where the build system is located.
Finally, we’ll combine everything we’ve learned into one makefile :
The load target loads the build module and the unload target deletes it from the kernel.
In our tutorial, we’ve used code from main.c and device_file.c to compile a driver. The resulting driver is named simple-module.ko. Let’s see how to use it.
Loading and using the module
To load the module, we have to execute the make load command from the source file folder. After this, the name of the driver is added to the /proc/modules file, while the device that the module registers is added to the /proc/devices file. The added records look like this:
The first three records contain the name of the added device and the major device number with which it’s associated. The minor number range (0–255) allows device files to be created in the /dev virtual file system.
Then we need to create the special character file for our major number with the mknod /dev/simple-driver c 250 0 command.
After we’ve created the device file, we need to perform the final verification to make sure that what we’ve done works as expected. To verify, we can use the cat command to display the device file contents:
If we see the contents of our driver, it works correctly!
Conclusion
In this tutorial, we’ve shown you how to write a simple Linux driver. You can find the full source code of this driver in the Apriorit GitHub repository. If you need a more complex device driver, you may use this tutorial as a basis and add more functions and context to it.
At Apriorit, we’ve made Linux kernel and driver development our speciality. Our developers have successfully delivered hundreds of complex drivers for Linux, Unix, macOS, and Windows. Contact our experienced team to start working on your next Linux driver development project!